
一直想深入的学习一下Hadoop,最近恰好用到这些知识,便重新拿起来研究一下,并做一些记录。
简单的来说,Hadoop是一套工具,包含了解决一些特定问题(如大规模数据处理、排序)的工具,提供了一个分布式运行环境来解决问题,而这个分布式环境具有良好的伸缩性。而构成整个分布式运行环境的有如下几个角色(节点):
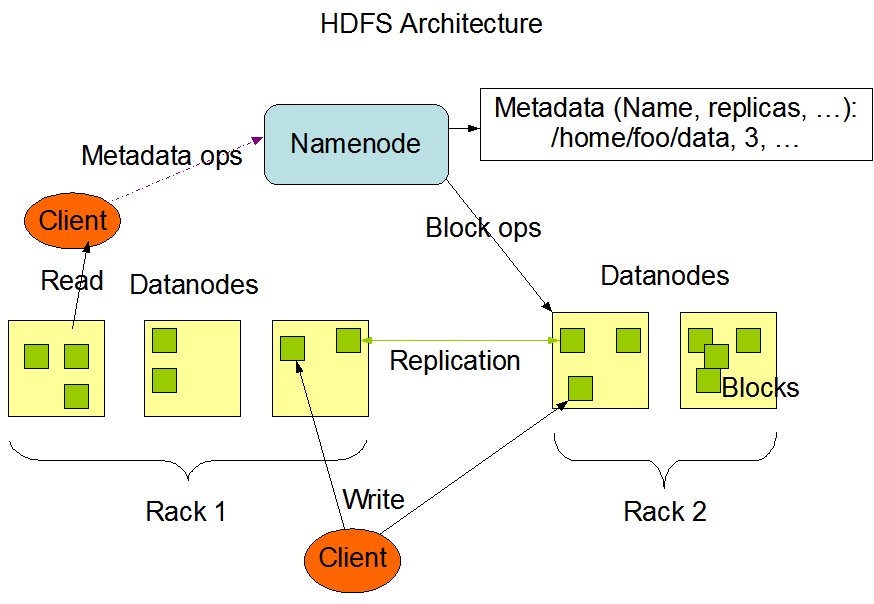
1、nameNode
顾名思义,这是一个元数据节点,目的是为了管理整个HDFS文件系统中文件的元数据信息,这些元数据信息包括文件系统树内所有的文件和目录,也包含着每个文件中各个块所在的数据节点(datanode)信息。
2、datanode
这是一个数据节点,他的职责是存放具体的数据并维护自身所存储的存储信息,这些数据是以数据块(block)为单位存放的,所以datanode自身维护一个存储块的列表并定期向namenode发送这些信息。
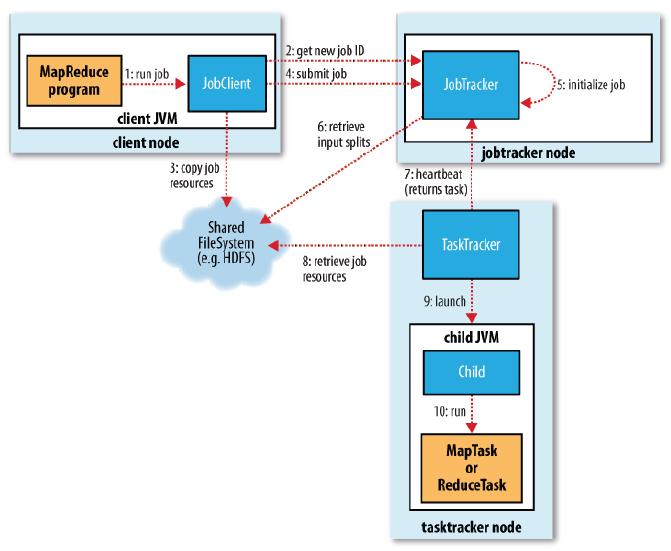
3、jobtracker:
jobtracker存在的意义是协调作业的运行,什么叫协调作业的运行呢?在我们运行一个map/reduce作业(job)的时候要向jobtracker提交作业信息,而本节点的作用就是维护这些作业,提供新建作业、处理作业所需资源、计算作业的输入分片、分配任务执行节点(tasktracker)等功能。
4、tasktracker
tasktracker即是具体任务的执行者,这里边之所以叫task而不是job,是因为job为一个map/reduce作业的总称,而到具体的tasktracker上所执行的可能仅仅是job的一部分,所以叫做tasktracker。tasktracker会运行一个简单的循环来定期发送心跳给jobtracker以确保jobtracke知道自己还”活着”并告知自己能否接受新的任务,这里便有一个数据本地化(data-local)和机架本地化(rack-local)的概念,jobtracker会考虑tasktracker的网络位置,并选取一个距离其输入分片文件最近的tasktracker,所以对于最理想的情况是由datanode上存放的数据(输入分片)直接输入到tacktracker上运行的任务,当然这个只对map任务有效。(map任务的输入为HDFS上的数据,而reduce任务则不是)。
这里面有两张图能说明以上所说的内容:
厉害!厉害!